



When confronted with the above question, the most straightforward and efficient method is to use a PDF editor that supports OCR. Here, a new problem arises: which OCR software should you use to recognize text from a scanned PDF? How to convert scanned PDF to editable text using OCR? Don't stress! This article will offer you an answer.
What Is OCR?
First things first, we need to straighten out the meaning of OCR technology. OCR stands for Optical Character Recognition, a process in which PDF programs convert scanned PDFs to text, a machine-readable format.
This widely used technology recognizes text and extracts it from a scanned PDF. Simply put, PDF to OCR converts PDF images to text by identifying characters using PDF OCR software.
Method 1: How to OCR a PDF with SwifDoo PDF
SwifDoo PDF is a versatile PDF editor on Windows that provides an advanced OCR tool. As a multitasker, it can help with PDF editing, annotation, password protection, and conversion.
To recognize text in a PDF, SwifDoo PDF uses an OCR (Optical Character Recognition) engine to make image-only PDFs editable. Additionally, it enables you to convert scanned PDFs to editable Word. Let’s take a look at how to OCR a PDF on Windows 10/11 using SwifDoo PDF:
Step 1: Download and install SwifDoo PDF from the official website or Microsoft AppSource.
Step 2: Launch the program and click on OCR in the Edit tab.
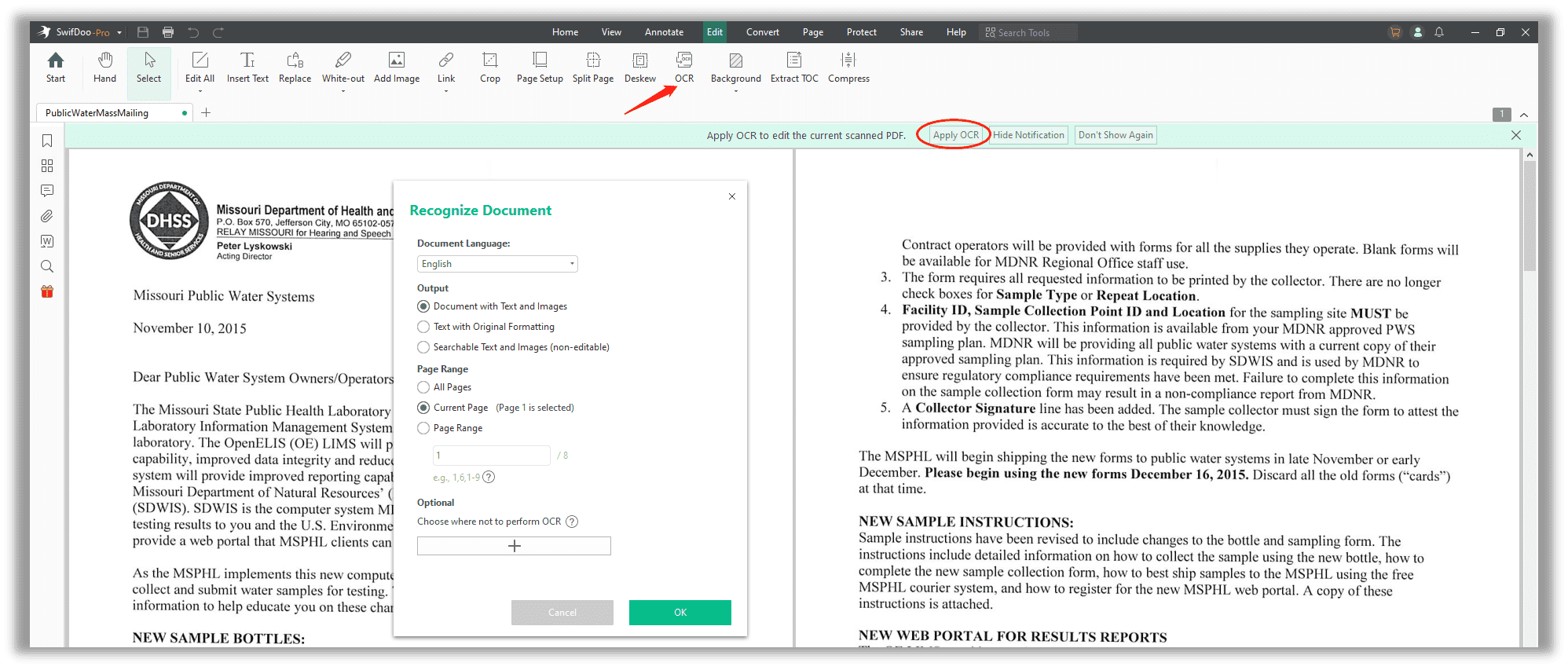
Step 3: In the Recognize Document window, users can choose how to OCR the current PDF document and convert the scanned PDF to a document with text and images; text with original formatting; searchable text and images, but non-editable; or pure text.
Step 4: When you decide how to output the OCR result, feel free to specify the page range to perform OCR if needed. Once ready, click OK to OCR the PDF.
How to check if a PDF is scanned or not
Some users may wonder how to tell whether a PDF file is an image-only PDF. Here are several identifiers:
Method A: Click on the "Edit" tab. If a window shows no editable content in the PDF, it is a scanned PDF.
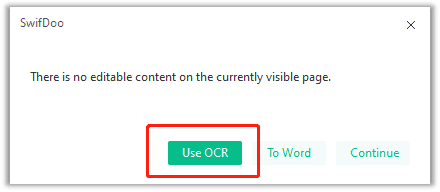
Method B: perform a PDF to Word conversion task. SwifDoo PDF will mark out the nature of the PDF next to the file name, just as the screenshot demonstrates.
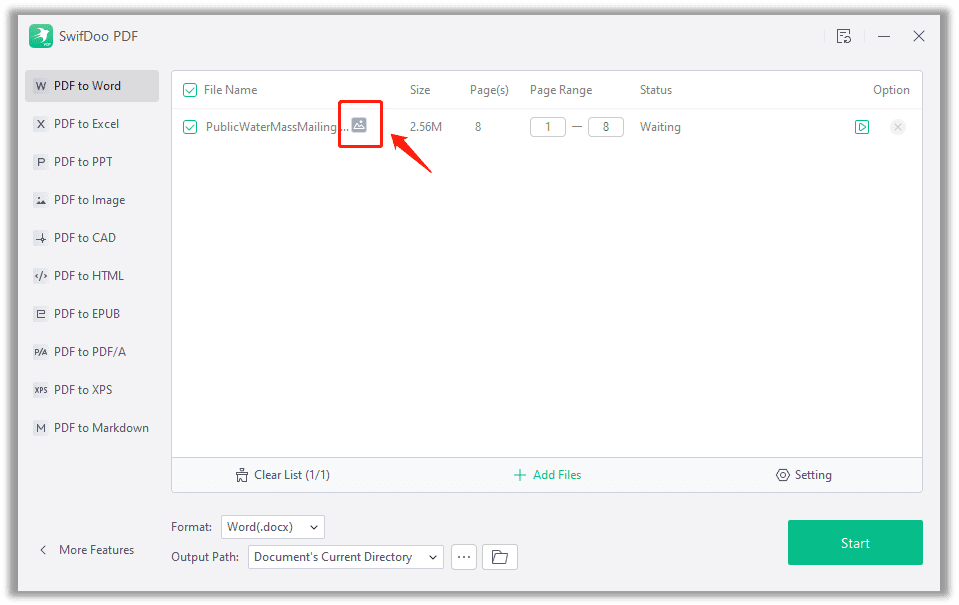
If you need to convert a scanned PDF to an editable Word document or text file, the conversion results may disappoint you, as the Word document after PDF text recognition is full of errors and wrong formatting. You can, however, optionally use an OCR tool, and the OCRed PDF will be saved in the same local folder as the original PDF.
Method 2: OCR a PDF with Soda PDF
Soda PDF is a powerful PDF tool that aims to make PDF-related tasks easier. It enables users to edit, reorder, annotate, and secure PDFs. The Windows-based PDF to OCR converter and its editing tools make editing a scanned PDF document possible. Take a look at how to convert an image PDF to a text PDF in Soda PDF:
Step 1: Download and install Soda PDF on your PC.
Step 2: Start the program to open the scanned PDF.
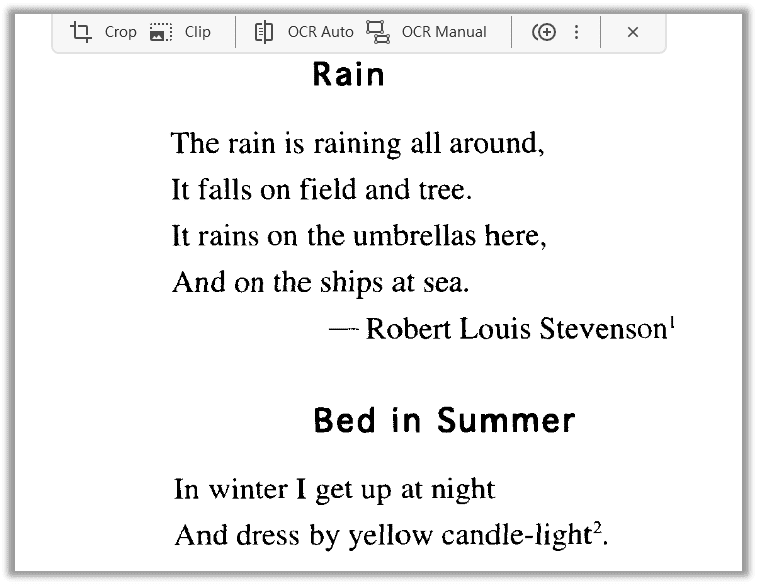
Step 3: Select OCR or click on any page of the image-only PDF to activate OCR mode. When you see the hanging menu bar, choose OCR Auto, and the PDF will be automatically converted to searchable, editable text from a scanned PDF.
Soda PDF provides two OCR modes to convert PDF images to searchable text: OCR Auto and OCR Manual. The main difference between these two modes is that the latter enables users to decide how the OCR engine interacts with their images, whereas auto mode automatically detects and scans the next PDF page. Manual PDF text recognition can detect text, images, and tables. Any area inside this red box will be converted to text.
Since a scanned PDF is made of layers of images, Soda PDF provides a “Crop” tool to allow for trimming PDF pages. In the meantime, users can move or copy any page for personal use by right-clicking on the PDF image.
Soda PDF is available both on Windows OS and the web. These two versions share the same user interface and features, with no other differences.
Method 3: Run OCR on PDF Using Adobe Acrobat Pro
How to OCR a PDF on Mac? Mac users can turn to Adobe Acrobat Pro to OCR a PDF to Word, Excel, text, or other editable files. The software can also correct the recognized text and straighten a scanned PDF to make it look perfect. When needed, it helps enhance scanned documents to get the text clearer and darker automatically. After text recognition, you can utilize its robust Edit function to change the text, images, layout, formatting, and more.
Explore how to OCR a PDF using Adobe Acrobat Pro.
Step 1: Open the PDF you desire to OCR in the new version of Acrobat on your PC or Mac.
Step 2: Click All tools in the top-left Menu button, then select the Scan & OCR tool.
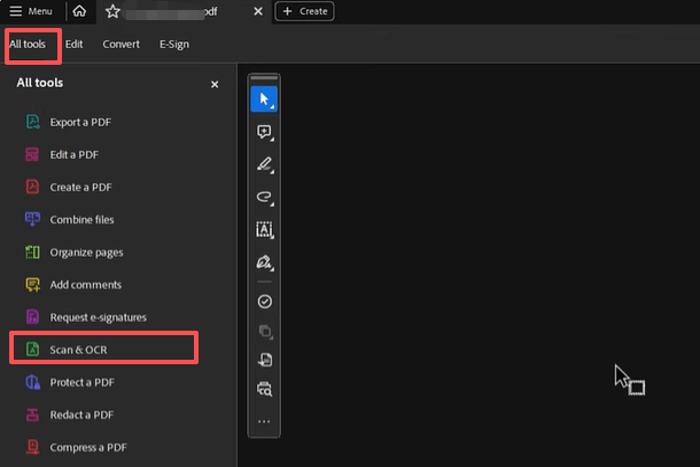
Step 3: Click the In this file button in the RECOGNIZE TEXT section, and hit the gear icon to open the settings window.
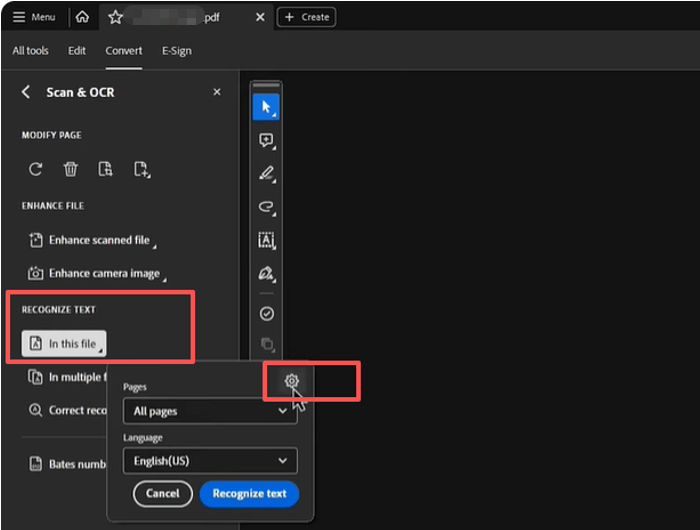
Step 4: Select whether to output the PDF to a searchable image or editable text with images, and set other output options.
Step 5: Apply the settings and click the Recognize text button to OCR the text from the PDF.
How to OCR a PDF for free? If you wonder about how to do PDF OCR on Mac or Windows for free, you can use the Adobe Acrobat online OCR tool. Create a free account, upload your PDF to the online Acrobat OCR page, click Recognize text, wait a moment, and you can click the three horizontal dots at the top to download this file. Then, you are able to edit the PDF in one of the best PDF editors.
Method 4: Cisdem PDF Editor OCR for Mac
For macOS users who need to perform PDF text recognition, things were more complicated until we found Cisdem. Cisdem and its relevant products are designed for Apple computers, including the spotlight of this section: Cisdem PDF Converter OCR for Mac. You can use it to convert scanned PDF to text on your Mac.
Cisdem PDF Converter OCR integrates a full set of useful tools for PDF-related tasks, including a PDF-to-OCR converter. Without further description, let’s get to know how you convert PDF images to text on Mac:
Step 1: Import the image PDF to the workstation by dragging or dropping the file on the interface, clicking the + button, or selecting File > Add file.
Step 2: Select the language of the original PDF document to improve recognition accuracy. Cisdem now supports 27 languages, meeting the basic needs of users.
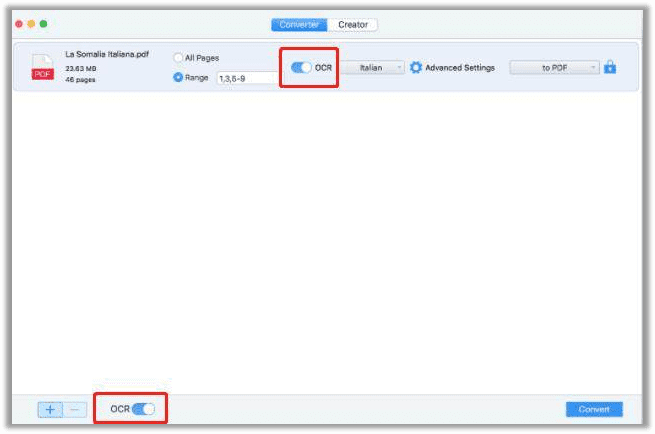
Step 3: At the Converter page, tick the OCR box to recognize text in this image PDF. Please be aware that there are two OCR buttons. The one next to the Range is only for the selected PDF, while the other one is to apply OCR on all PDFs.
Step 4: Select DOCX from the output format drop-down and click Convert. Then choose the output folder and click on Save to finalize the process of converting an image PDF to a text PDF on Mac.
Additionally, users can choose “Advanced Settings” to manually adjust the recognized text, images, or tables.
Method 5: How to OCR a PDF in Google Docs
For someone who prefers to use a free web-based OCR converter for PDF text recognition, this cloud storage platform may be a good option. It’s hard to imagine Google Docs performing such a task. The truth is, according to the Google Drive Help Center, this online application can convert PDF images to text. The following is how to do it:
Step 1: Log in to your Google Drive account, then click the New button below the Drive icon.
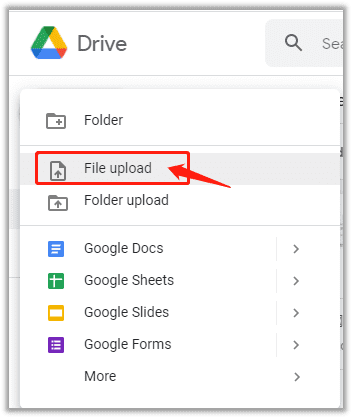
Step 2: In the drop-down menu, choose File upload to import a local PDF document to the workspace.
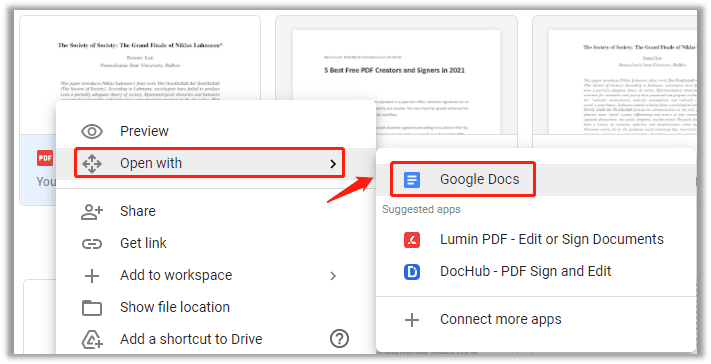
Step 3: Right-click on the uploaded PDF and choose Open with > Google Docs to convert the scanned PDF into an editable Word document. When you are directed to the Google Docs page, you are free to output the Word file locally.
The process of OCRing a PDF document in Google Drive is not complicated, though. Please pay attention to some limits of this free online OCR tool before you start:
- File size: Your file (.jpg, .png, .gif, or PDF file) should be kept within 2 MB.
- Resolution: Text should be at least 10 pixels.
- Orientation: Documents should be right-side up.
- Font styles: Make sure the font in your file is common, such as Arial or Times New Roman.
![How to Edit a PDF in Google Drive [June 2026]](https://img.swifdoo.com/image/How to Edit a PDF in Google Drive.png)
How to Edit a PDF in Google Drive [June 2026]
How do you edit a PDF in Google Drive? Are you looking for the answer? The article demonstrates a freeway and advanced PDF editing option.
READ MORE >Method 6: How to OCR a PDF Online with OCR Space
OCR Space is an online OCR service provider, free of charge. At the same time, this free OCR software is an open-source program that provides a free OCR API key for developers. As a free tool, OCR Space simplifies the conversion process, and hence users only need to make a couple of clicks to recognize PDF text. Let’s dive into the process of how to OCR a PDF online:
Step 1: Enter the URL in the search bar and select Choose file to upload the PDF.
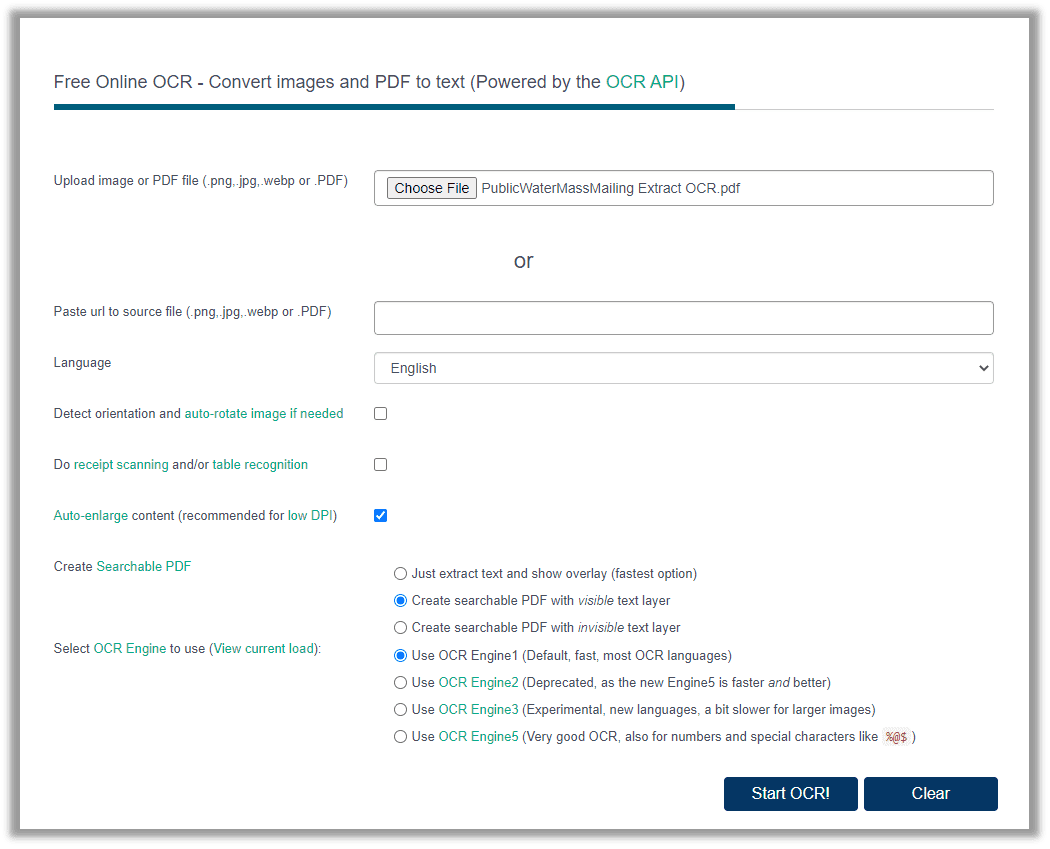
Step 2: Choose the language of the original PDF document and tick the recognition or orientation if needed. Besides, users are enabled to create searchable PDFs by changing how the PDF is displayed in Create Searchable PDF.
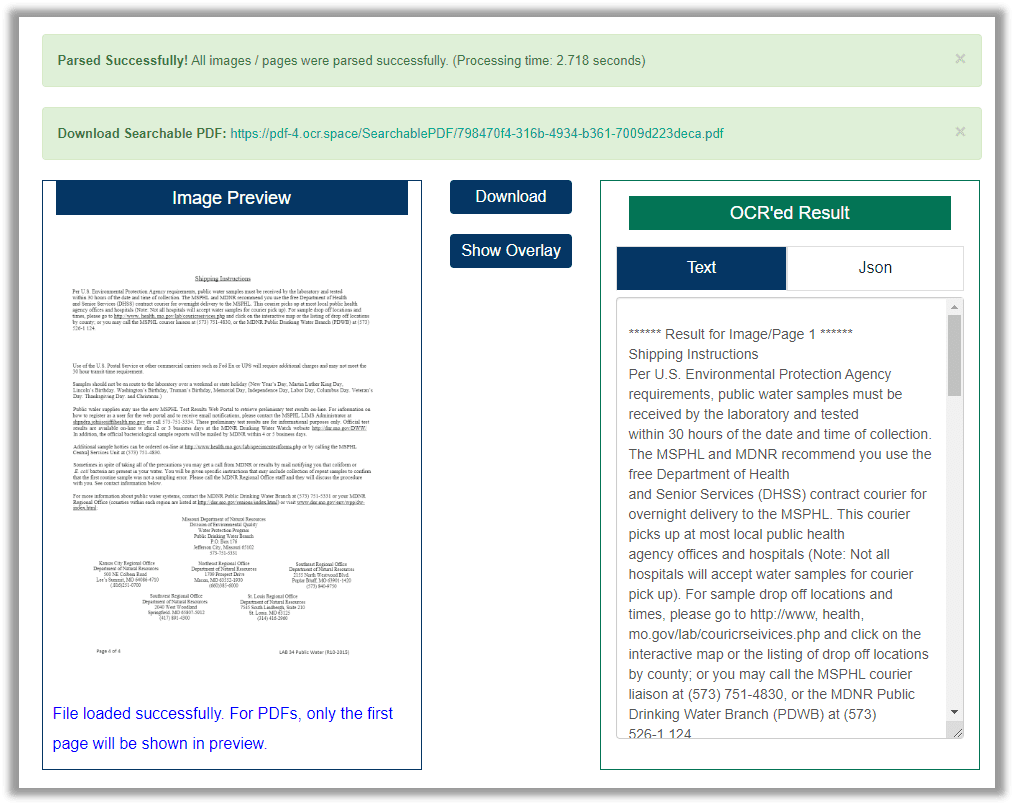
Step 3: Once ready, press the Start OCR! button to output the scanned PDF into a selectable DOCX document.
You can click "Download" to access the text PDF. This PDF tool offers a preview of the OCR results so that it’s convenient to check whether the text PDF meets the standard.
Final Thoughts
In conclusion, this post has demonstrated how to OCR the scanned text from a PDF. Online OCR tools are free to use, but their OCR capabilities may be overshadowed by the desktop PDF OCR software, particularly when it comes to an image-only PDF written in multiple languages (a textbook, for instance). However, desktop PDF OCR programs offer only limited free trials, whereas SwifDoo PDF offers a 7-day free trial.
If your target is to translate a scanned PDF, SwifDoo PDF also offers translation tools.



