

Are you tired of manually copying and pasting data from PDF tables? Manually copying and pasting data from PDF tables can be time-consuming and prone to errors. Luckily, there are several tools and techniques that can help you extract tables from PDFs quickly and easily. In this article, we'll show you how to use Python libraries to extract tables from PDFs programmatically. We'll also provide tips and tricks for manual extraction methods, as well as using a dedicated PDF tool. Let’s move forward to see how.

SwifDoo PDF: Extract Tables from PDF on Windows
SwifDoo PDF is a user-friendly PDF editor that allows you to extract tables from PDFs in just a few clicks. With SwifDoo PDF, you can extract tables to a variety of formats, including Excel and CSV. This powerful software simplifies the process and saves you time.
To extract tables from PDFs using SwifDoo PDF, several methods can be used: convert PDF to Excel/CSV, take screenshots of pages in PDFs, etc. Here, we’ll show you how to get a table from a PDF within 3 steps:
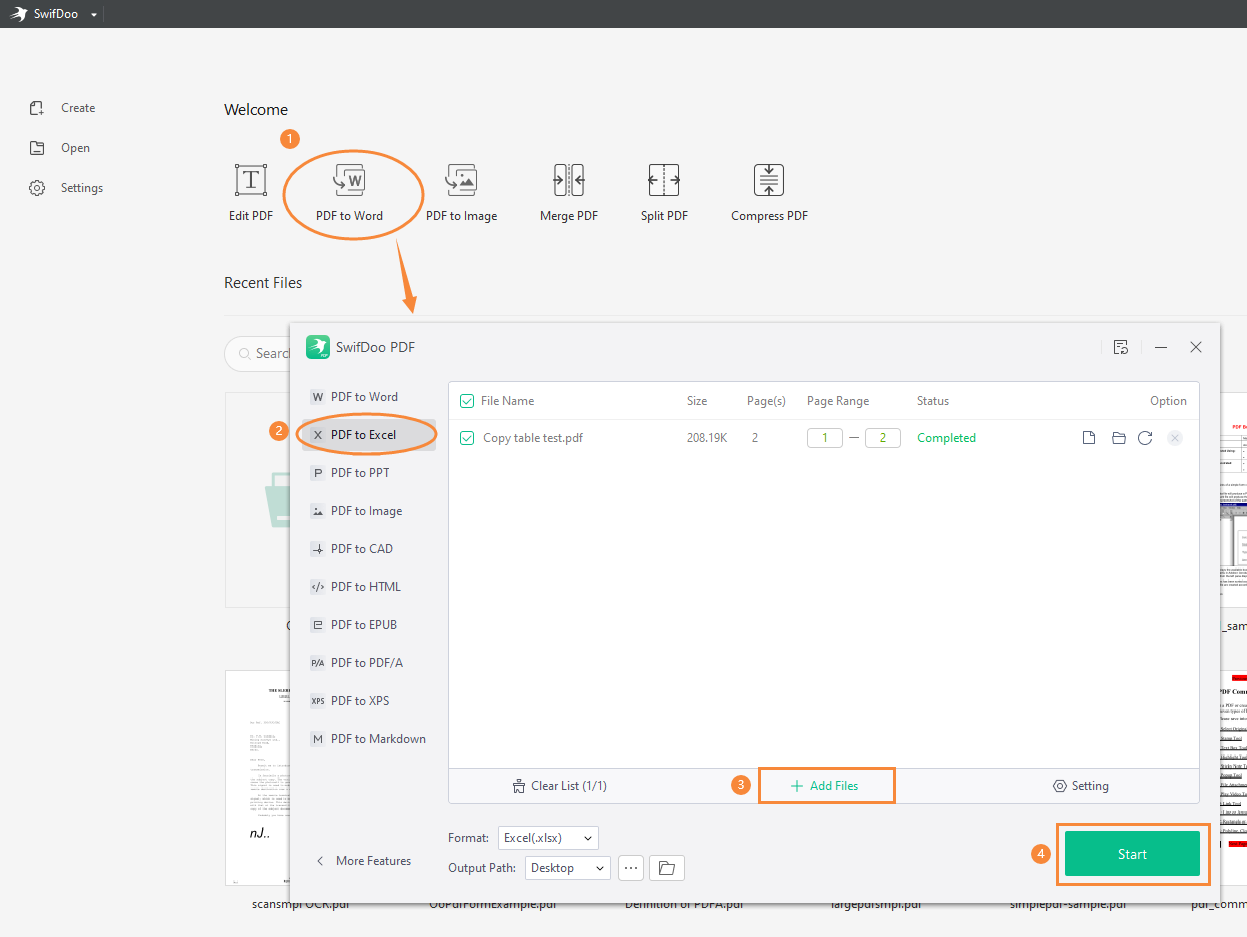
Step 1. Free download SwifDoo PDF and launch it.
Step 2. Click PDF to Word on the homepage and select PDF to Excel.
Step 3. Import the PDF file that contains tables. Then tap the Start button and get the table in Excel.
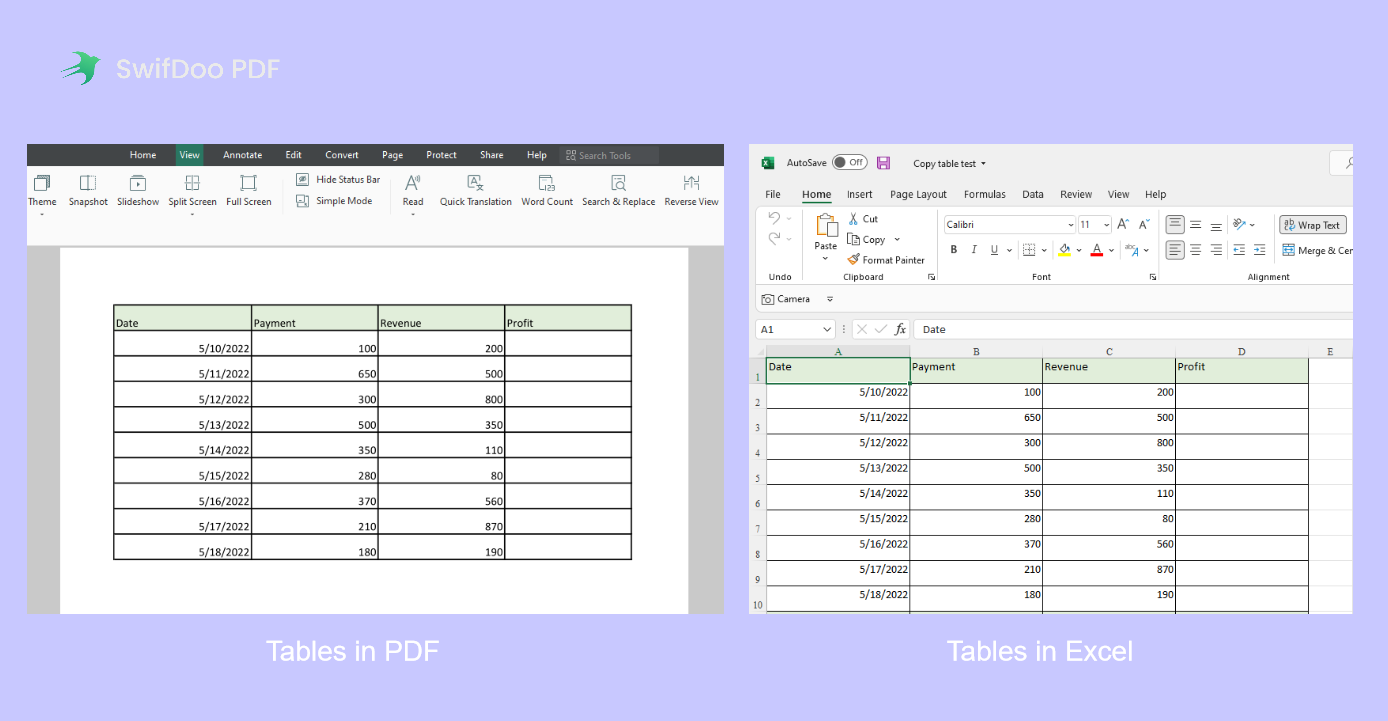
By exporting PDFs to Excel spreadsheets, all tables in your PDFs will be withdrawn naturally. And SwifDoo PDF keeps all tables’ style and format unchanged as they were created. What’s more, all users are granted with a 7-day free trial without any limit on the file number or size, making SwifDoo PDF a good alternative to Adobe Acrobat.
Microsoft Excel: Get Table Data for Free
Actually, Microsoft Excel can also help extract tables from PDFs straightforwardly since it can get data from PDF, TXT, XML, and many other online services and sources. For causal users with basic requirements, using Microsoft Excel can be the simplest and most direct way to get tables from PDFs. Here’s a detailed guide:
Step 1. Launch Microsoft Excel on your computer.
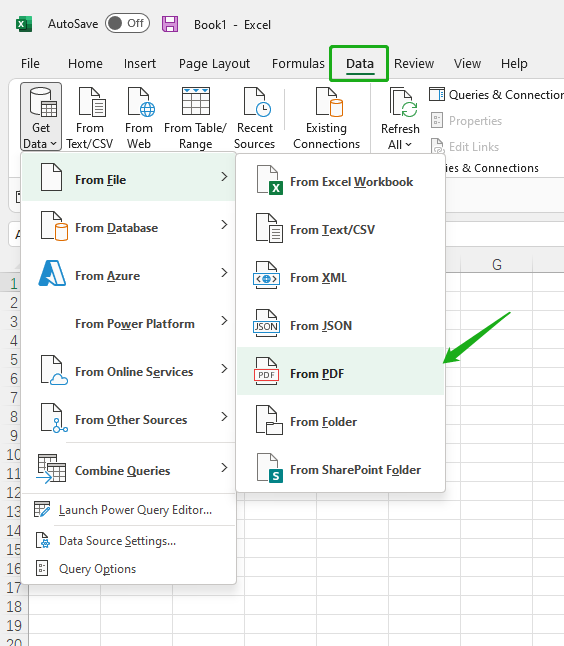
Step 2. Click Data from the top navigation bar and tap Get Data from the submenu.
Step 3. Hover your mouse on From File and select From PDF.
Step 4. Locate the PDF file you want to extract tables from and open it.
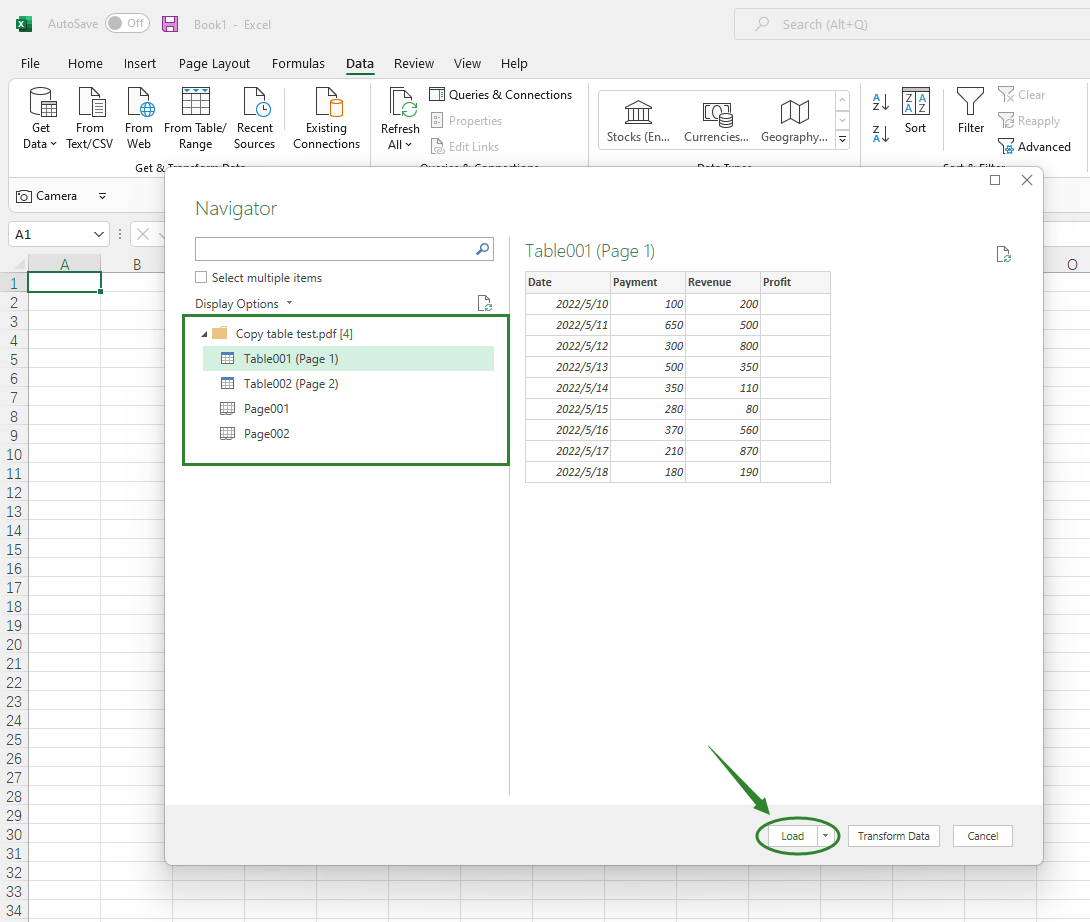
Step 5. Select the table you want to copy from the Navigator window and hit Load in the bottom right corner.

10 Best PDF Translators That You Must Know in 2026
Check this post to find out the 10 best PDF translators in 2025. We've tested and selected them from different aspects to help you translate your PDF documents.
READ MORE >Python Libraries: Extract Tables from PDF Python
If you prefer to use Python to extract tables from PDFs, you can use libraries such as tabula-py, PyPDF2, and Camelot. These libraries allow you to extract tables from PDFs programmatically and automate the process.
For example, tabula-py is a Python wrapper for the tabula Java library, which can be used to extract tables from PDFs. You can install tabula-py using pip and then use the following code to extract tables from a PDF file:
bash
Copy code
import tabula
# Read PDF into DataFrame
df = tabula.read_pdf("example.pdf")
# Extract first table
table = df[0]
# Convert table to CSV
table.to_csv("table.csv")
This code reads a PDF file into a DataFrame using tabula-py and then extracts the first table. Finally, the table is converted to a CSV file.
Adobe Acrobat: Export PDF Tables with Ease
If you prefer manual extraction methods, there are several options available. One method is to use Adobe Acrobat's Export feature. You cannot avoid Adobe Acrobat when looking for solutions to address PDF-related issues, since it’s the most professional PDF editor on the market. Though it’s expensive and too overwhelming for most users, Adobe Acrobat still stands on the top of the list.
Here’s how to extract tabled from PDF with Adobe Acrobat DC.
Step 1. Open your PDF file in Acrobat DC.
Step 2. Head to the Tools center and select Export PDF.
Step 3. Select Spreadsheet and checkbox Microsoft Excel Workbook.
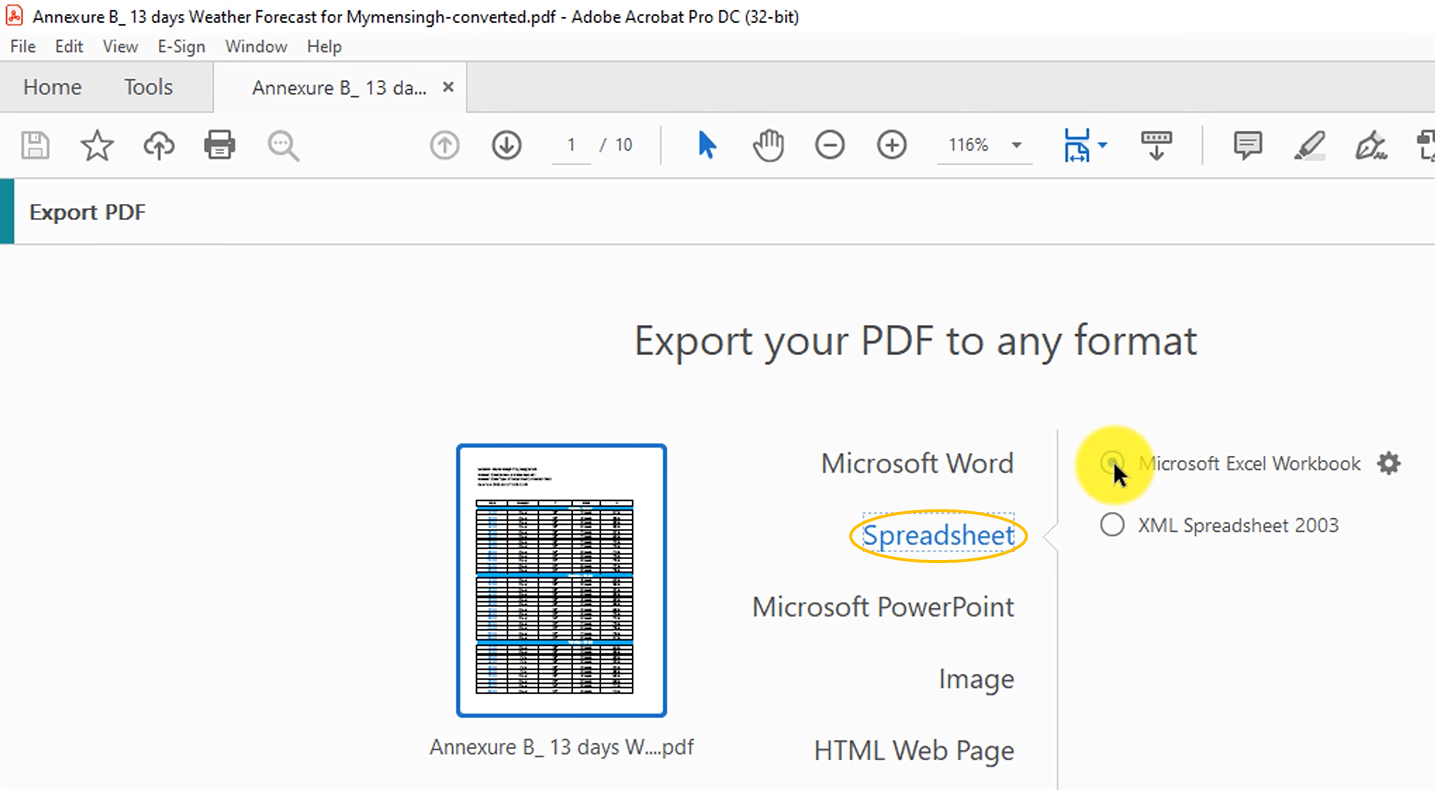
Step 4. Click on Export. Then select a directory for saving this spreadsheet.
Step 5. Rename it and click Save to confirm your changes.
To help extract tables from a PDF file, Adobe Acrobat also helps convert PDF to Excel in the first step. However, unlike SwifDoo PDF, this program only output your table as plain text, and you need to add the table format manually, which could be a flaw.
Conclusion
Extracting tables from PDFs can be a time-consuming and frustrating task, but with the right tools and techniques, it can be done quickly and easily. SwifDoo PDF offers a user-friendly way to extract tables from PDFs, while Python libraries such as tabula-py provide a way to automate the process using code. And if you prefer a manual method, SwifDoo PDF or online conversion tools can do the job as well.



